Data Understanding is about exploring how to inventory, assess, and plan for the data you need to power your AI solution.
AI projects are like a car, and you can’t drive anywhere if your car doesn’t have any gas. Which means without the right data, your AI project simply won’t move forward.
In many cases, we see that teams either don’t have the data they need or they don’t know what data they need in the first place.
This phase focuses on pinpointing exactly which data matters and whether you have enough of it, both in quantity and quality.
In CPMAI phase 1 (Business Understanding), we ask why we need AI to solve this problem, and in phase 2, we ask what data is needed to support those AI business requirements. Figuring out the type, quantity, and quality of data required for an AI solution ensures you’re on solid ground as you move on to preparing and modeling that data.
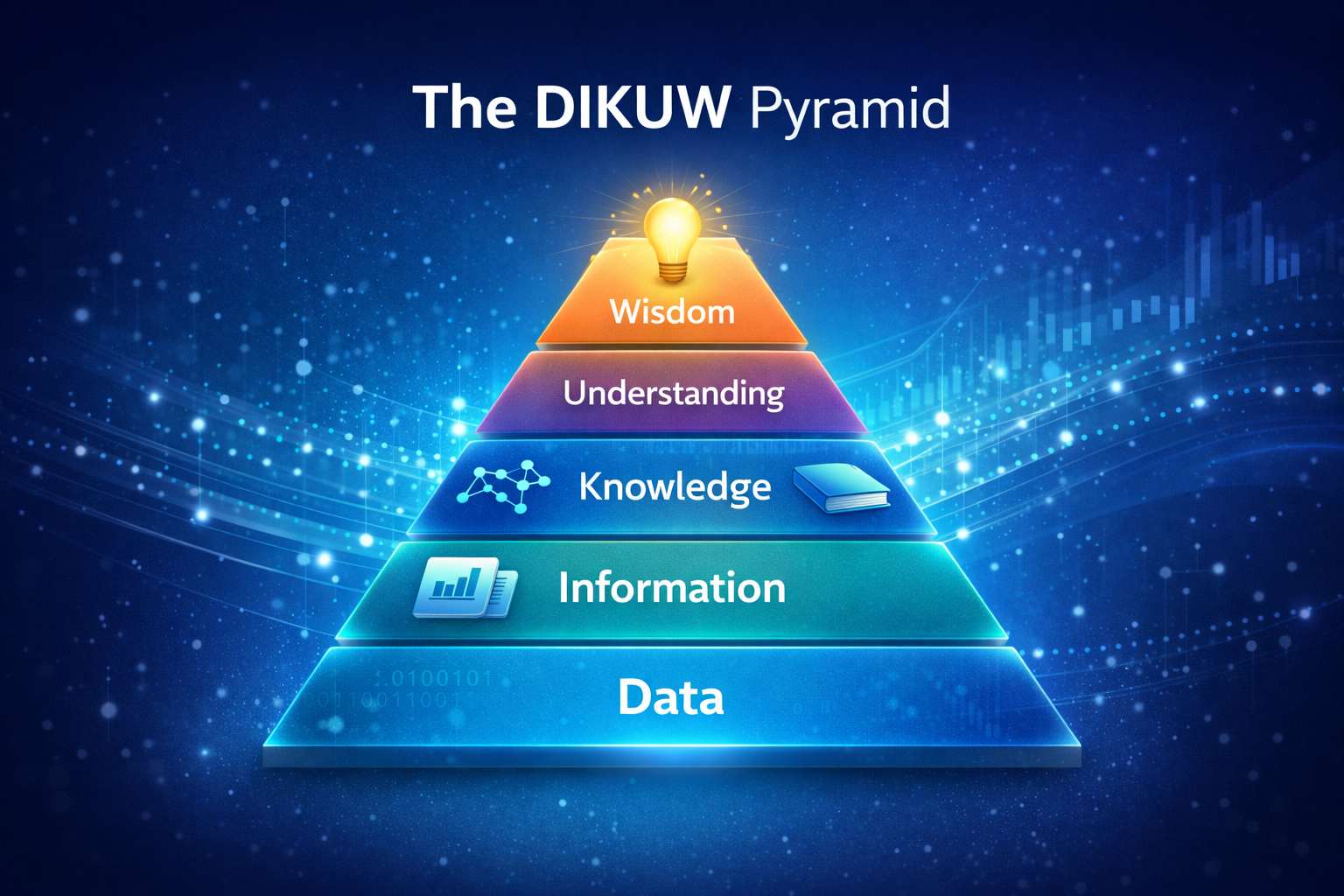
The DIKUW Pyramid – Data Understanding
Helps visualize the role of data in AI.
DATA, INFORMATION, KNOWLEDGE, UNDERSTANDING, WISDOM
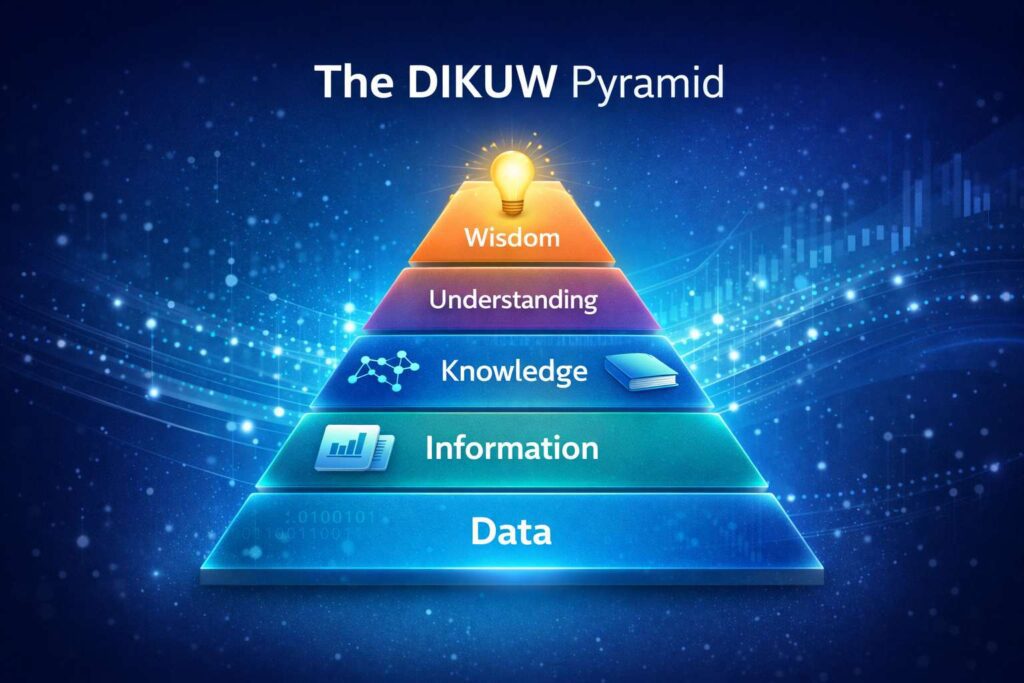
This shows the increasing value of intelligence with data.
Data
At this level of value, we’re dealing with raw facts at the foundational layer. Our primary needs here are storing and processing data. So we get some value from the data, but by itself, simply storing and retrieving that data doesn’t tell you much.
Information
By organizing, analyzing, and summarizing data, we can get more value from our data. We can answer not just basic facts of data, but also some questions, such as “Who did what? Where did this happen? When? Or how much?”
At this level, we apply analytics and reporting solutions, but we can get even more value from our data.
Knowledge
We can identify patterns and gain deeper insights, like predicting future outcomes or grouping similar items.
As we move up the pyramid, we also need to apply more sophisticated technology to get more value from data, whereas we only need databases and data stores at the D level and reporting and analytics tools at the I level.
At the K level, machine learning enters the picture. The K level gives us the power to spot patterns in the data, such as conversational patterns or recognition patterns. It also allows us to predict outcomes and determine next steps.
Sounds familiar, right? The seven patterns of AI. But we can get even more value from data.
More than just knowing the patterns, understanding what those patterns represent is at the U level – a level that is often missing in similar diagrams.
Understanding
We need reasoning to understand why something is happening.
Today’s AI often struggles here because it requires more than just pattern recognition. The lack of understanding is why many AI systems hallucinate or produce clearly incorrect results.
We need something even more sophisticated than machine learning to give us the understanding we need for more complex reasoning.
Wisdom
At this level, human-like judgment and nuanced decision-making come into play.
The W level is where we determine when and why certain things should be done instead of just recognizing or understanding the patterns to be able to make truly intelligent decisions, respond in environments of ambiguity, and handle all sorts of intelligent needs that our brains are capable of.
In CPMAI, we use the DIKUW Pyramid to understand where AI can and cannot add value.
If you’re trying to solve a data storage problem or a simple reporting problem at the Data or Information levels, you might just need databases and business intelligence tools.
AI tools are really not the best fit for more basic aspects of data handling and reporting.
Once you hit the Knowledge level and want to detect patterns or make predictions, that’s where AI or machine learning can really shine.
Machines still struggle with reasoning and common sense.
So while AI systems are starting to make progress with dealing with understanding-level problems, they still exhibit a lot of unpredictability and problems that can pose a risk.
We haven’t yet been able to build machines with a sort of consciousness and higher-level understanding to address wisdom-level problems.
Aiming for the right level for your AI project will help ensure that AI remains a good solution to your business problem.
In CPMAI phase two, we need to understand how big data comes into play.
The characteristics of big data are often described by the V’s of big data.
VOLUME
- How much data do we need?
- Are we dealing with massive amounts of data that make traditional processing methods difficult to manage?
VELOCITY
- Is your data constantly changing?
- Does your AI system need to deal with real-time changing data like social media feeds or sensor data from machinery?
VARIETY
Data can come in a variety of forms, such as images, text documents, audio recordings, and sensor data, each requiring different handling.
VERACITY
Veracity addresses data inconsistencies, missing values, or issues of poor data quality.
Unstructured and Structured Data
Structured Data
- Can be displayed in rows, columns and relational databases
- Numbers, dates and strings
- Estimated 20% of enterprise data (Source: Gartner)
- Requires less storage
- Easier to manage and protect with legacy solutions
Unstructured Data
- Cannot be displayed in rows, columns, and relational databases
- Images, audio, video, word processing files, e-mails, spreadsheets
- Estimated 80% of enterprise data (Source: Gartner)
- Requires more storage
- More difficult to manage and protect with legacy solutions
The majority of data in most organizations is unstructured…
FOR EXAMPLE: EMAILS, PDFs, IMAGES, SOCIAL MEDIA POSTS
Structured data is much easier to query and manipulate, but there’s a lot more of the unstructured type around. We need ways to get value from the unstructured data, just like we do from structured data.
That’s where machine learning can shine, because it’s specifically designed to interpret and learn from these unstructured sources.
If your data is already neatly stored in rows and columns, you may not even need AI.
But if you have a mountain of emails or documents that need to be searched or categorized, that’s a prime opportunity for an AI project, so long as you have enough of the right data.
In addition, we need to deal with the fact that not all data is equally reliable. This is where the data veracity questions that we just covered will be useful.
Here are some key questions to ask.
- What data is required to achieve our objectives? Clearly define the specific data needed to solve the business problem identified in Phase One.
- Do we have enough data, and is it reliable? More data is not always better. The focus should be on clean, accurate, and representative datasets, free from significant errors or bias.
- Which internal and external data sources are necessary? Identify all relevant data sources across the organization and from external partners or providers.
- What additional data would strengthen our existing dataset? Determine any gaps and the data needed to improve coverage, accuracy, or insight.
- What are the ongoing data collection and preparation requirements? If data changes frequently, establish a strategy for continuous collection, validation, and updates.
- What technology is required for data processing and transformation? Assess the need for data pipelines, ETL processes, transformation tools, and labeling workflows.
- Are there special considerations for unstructured data? Data such as text, documents, images, and audio may require specialized preprocessing techniques or machine learning models.
If you don’t have the right data, or if it’s not in good shape, you could spend a lot of time and money building a model that never performs well.
So here in Phase 2, you’re setting yourself up for success by mapping out your data sources, spotting potential problems early, and forming a plan to address them.
There are several common pitfalls to address during CPMAI Phase 2: Data Understanding:
- Data redundancy or gaps
You may encounter duplicate datasets or discover that entire categories of required data are missing. - Poor-quality or noisy data
Outdated records, inconsistent labeling, missing values, or biased data can significantly reduce the accuracy and reliability of AI systems. - Unsupported data formats
Challenges arise when data exists in formats that your current tools, infrastructure, or team skills cannot effectively process. - Unclear data ownership or permission issues
Risks emerge if you lack the legal rights, access permissions, or governance clarity to use certain datasets.
Data-related issues are far easier and less costly to resolve when identified early.
That is precisely the purpose of Phase 2: Data Understanding.
By the end of Phases 1 and 2, you have clearly defined the business case for the AI initiative and developed a solid understanding of the data required. This foundation enables you to move confidently into the next phase, where data can be properly transformed, cleaned, and labeled for effective AI development.
Connect with us if you have any questions. In case you haven’t read about phase 1, do read. And you need to hire freelancers to help you manage or execute your AI projects. Reach out to our team of freelancers.

