
Data Preparation is the third phase of CPMAI—and it’s where the real work begins. In most AI initiatives, the majority of effort is not spent on training models, but on getting the data ready.
In fact, nearly 80% of the time in each AI project iteration is typically dedicated to collecting, cleaning, integrating, labeling, and otherwise preparing data for use.
Messy or incomplete data is like a car without fuel. No matter how advanced the engine, it won’t take you anywhere.
If you discover midway through the project that the data is overly complex, unmanageable, or misaligned with the objective, it often signals that the problem scope should have been tighter from the start.
Fortunately, CPMAI is designed to be iterative. If new insights reveal the need to refine the scope or switch to a more appropriate dataset, the framework allows you to revisit earlier phases and course-correct before moving forward.
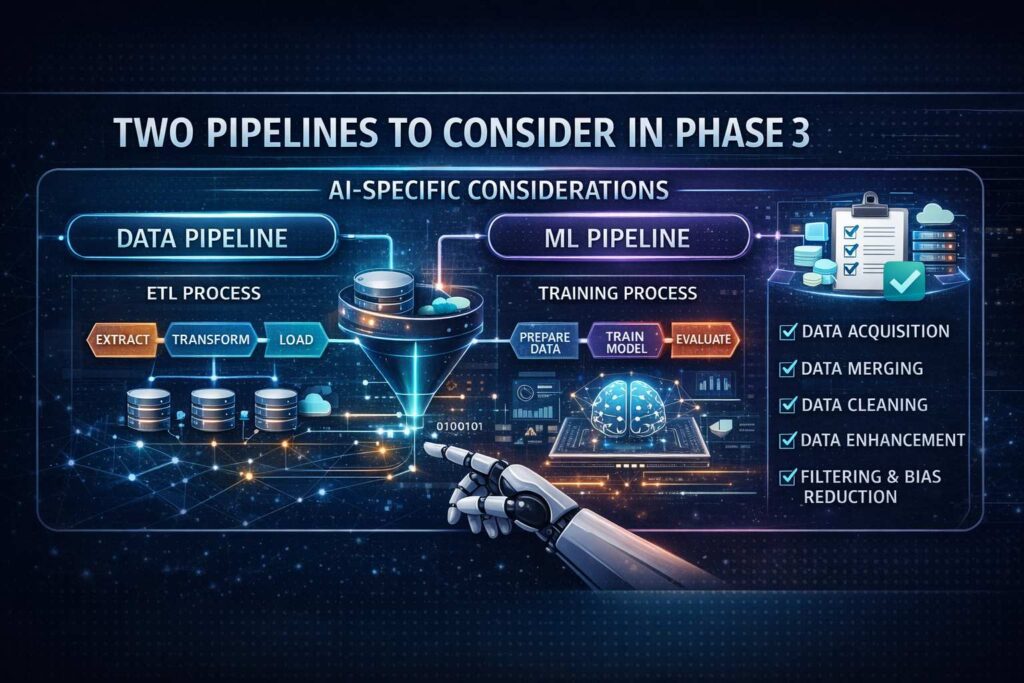
The Data Pipeline
The first crucial step in phase three is to design and build your data pipeline.
This pipeline is simply the route your data takes from its original source to the AI system.
TWO PIPELINES TO CONSIDER for Data Preparation:
Training Data Pipeline: The training data pipeline is where you gather, clean, and format historical or existing data to teach your model before it’s built and in use.
Inference Data Pipeline: The inference data pipeline handles the real-time ongoing flow of new and production data that the model will process once it’s deployed.
At this point in the process, you haven’t yet built your AI system. So by planning these pipelines before you start building, you can spot potential issues early.
Maybe you have multiple data sources that each require different cleaning steps or transformations, or perhaps some data is in a format you can’t process efficiently.
Addressing this before you’re deep into building and delivering your AI solution will save a lot of time and trouble down the road.
Data preparation isn’t the glamorous part of AI, but it’s one of the most critical parts.
Building efficient, well-planned data pipelines and thoroughly cleaning and labeling your data will give your AI project the best chance for success.
AI-Specific Considerations for Data Preparation
Data Acquisition in Data Preparation
Define how data will be collected. This may include internal databases, APIs, streaming sources, or third-party providers.
Ensure data ownership is clear and that you have the appropriate permissions and usage rights.
Data Merging in Data Preparation
When data originates from multiple sources, careful integration is required. Differences in naming conventions, schemas, or data types must be reconciled.
Identify and eliminate duplicate records that could distort results or disrupt data pipelines.
Data Cleaning in Data Preparation
Address data quality issues by removing corrupted records, resolving inconsistencies, and managing missing values.
Standardize formats where necessary—for example, aligning date formats or ensuring numeric values use consistent units.
Data Enhancement in Data Preparation
Enhance the dataset by deriving additional features that improve model performance. For instance, timestamps can be transformed into features such as day of the week or time of day.
Consider data enrichment or augmentation techniques, such as generating additional samples or synthetic variations, to improve robustness.
Filtering and Bias Reduction in Data Preparation
Identify and correct data that may introduce bias. This may involve balancing category representation, removing misleading outliers, or excluding data that does not reflect real-world conditions.
Critically important—consideration is data labeling.
In supervised learning, one of the three core machine learning paradigms, models learn from labeled examples. This means the training data must be accurately and consistently labeled.
For example, if you are building an image recognition system to identify cats, your dataset must clearly label images of cats—and exclude or correctly distinguish dogs, rabbits, or unrelated objects.
Data labeling is both time- and resource-intensive. Attempting to label massive datasets all at once can quickly become unmanageable. A more effective approach is to begin with a smaller, well-defined subset to validate your assumptions and methodology before scaling.
Large challenges are best tackled incrementally—by breaking them into smaller, manageable pieces.
Ensure you have both the budget and the right expertise in place to perform data labeling accurately and consistently.
If labeling proves to be too costly or time-consuming, that’s a strong signal to reassess the project scope. In some cases, a semi-supervised or unsupervised approach may be more practical. Alternatively, an off-the-shelf model that can be aligned to your business requirements may offer a faster and more economical path.
The iterative nature of CPMAI provides this flexibility.
You may discover that your data supports only a portion of the original problem—or that time and budget constraints limit how much data can realistically be prepared. That’s not a failure. It’s the strength of an iterative framework: you can return to Phase 1 or 2, refine your objectives, and continue moving forward with clarity.
Finally, if nearly 80% of AI effort is spent on data engineering, it’s essential to staff accordingly.
This often includes data engineers, data analysts, and domain experts who understand where the data resides and how it should be interpreted. Cutting corners on these roles almost always leads to delays, rework, and frustration later in the project.
By the end of Data Preparation CPMAI Phase 3, you should be able to answer these questions.
- How should data be cleaned and prepared to meet project requirements?
- How can we create repeatable steps for data engineering?
- How can we continuously monitor and evaluate data quality?
- How can we effectively use or modify third-party data?
- When and how should humans be involved with data labeling?
- What additional steps can we take to augment data?
If you can confidently address these areas, you’ll be well-positioned to move into Phase IV: Model Development—where the focus shifts to selecting and applying the AI tools best suited to solving the problem at hand.
Connect with us if you have any questions. In case you haven’t read about phase 2, do read. And you need to hire freelancers to help you build or manage your AI projects. Reach out to our team of freelancers.

